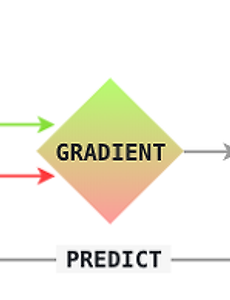
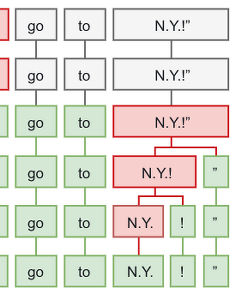
2018/0411 spaCy 사용하기 - Training Models spaCy의 훈련 로직은 대충 아래의 그림과 같다. training data는 text와 label로 구성이 되어져 있고, Model에서는 해당 text에 대해 label을 예측한다. 정답과 비교해서 차이만큼 gradient를 적용하고 이런식으로 반복함으로써 모델을 update하는 구조이다. spaCy에서는 GoldParse라는 class를 지원하는데 이걸 이용해서 모델을 학습할 수도 있다. entity 학습의 경우 BILUO scheme를 따른다. 또한 학습 성능을 향상시키기 위해 dropout을 적용할 수도 있다. 아래는 간단하게 모델을 업데이트 하는 코드를 설명하고 있다. english 타입의 빈 모델을 만들고, training data를 적당히 섞어 준 다음에 data를 1개씩 가져와서 모델을 업.. 2018. 4. 24. spaCy 사용하기 - Vectors & Similarity spaCy에서는 vector similarity 기능도 제공을 해 주고 있다. 또한 아래와 같이 vector를 가지고 있는지, norm 값(여기선 L2 norm), out of vocabulary 인지 등도 확인해 볼 수 있다. 문서간의 유사도도 확인해 볼 수가 있다. 홈페이지에서는 주변 단어와의 연결 관계 등을 고려해서 철자가 틀려도 비슷한 유사도를 나타낸다고 쓰여져 있는데, 결과 값이 별로 좋지 못한 관계로 이 부분은 그냥 스킵.. 자신이 직접 단어 벡터를 추가할 수도 있다. (이게 의미가 있나...) glove vector를 추가할 수도 있다. 그 밖의 fastText vector와 같은 다른 벡터들도 추가할 수가 있다. 핵심은 ' '으로 구분하고 첫번째 요소는 단어 2번째는 vector 값의 형태.. 2018. 4. 23. spaCy 사용하기 - multi-processing 과 serialization spaCy는 아래와 같이 nlp.pipe를 이용해서 병렬 처리가 가능하다. for doc in nlp.pipe(texts, batch_size=10000, n_threads=3):pass 아래의 코드는 Joblib와 spaCy를 이용해서 multi process를 구현한 코드이다. 자세히는 잘 모르겠다. -_- 또한 spaCy에서는 model을 저장 혹은 불러올 수가 있다. # 모델 저장 text = open('customer_feedback_627.txt', 'r').read()doc = nlp(text)doc.to_disk('/customer_feedback_627.bin') # 모델 load from spacy.tokens import Docfrom spacy.vocab import Vocab do.. 2018. 4. 22. spaCy 사용하기 -Processing Pipelines 우리가 spaCy를 사용하기 위해 nlp 객체에 text 파라미터를 입력하면 결과적으로 아래와 같은 pipeline이 실행 된다. 아래와 같이 model을 호출하면, spaCy에서는 처음에 model의 meta.json을 읽는다. meta.json에는 model name과 language, description pipeline이 json 포멧으로 나타나 있다. nlp = spacy.load('en') {"name": "model_name","lang": "en","description": "model description", "pipeline": ["tagger", "parser"]} spaCy에서는 model.json에 나타난 pipeline을 읽고 해당 pipeline을 처리한 후 결과 Doc 객체를.. 2018. 4. 21. spaCy 사용하기 - Rule based Matching spaCy에서는 자신이 직접 pattern을 등록시킬 수가 있다. 아래의 조건을 가지는 문자열 패턴을 찾는다고 가정해보자. 1. 소문자가 hello와 매칭되는 경우 2. 쉼표나 콜론 등의 구분자가 존재하는 경우 3. 소문자가 world와 매칭되는 경우 아래는 위의 조건을 코드로 나타낸 것이다. 아래와 같이 두 개 이상의 패턴을 등록할 수도 있다. wildcard token pattern도 등록할 수가 있다. 가령 User name: {username} 이런 형태의 패턴을 등록하고 싶을 경우 아래와 같이 username 항목에 빈 중괄호를 넣어 주게 되면 wildcard 처럼 동작하게 된다. ['ORTH': 'User'}, {'ORTH': 'name'}, {'ORTH': ':'}, {}] 대규모의 용어를 .. 2018. 4. 20. spaCy 사용하기 - tokenization spaCy에서는 아래와 같은 방식으로 tokenization이 발생한다. 우선 whitespace 기준으로 raw text를 분리하고, 왼쪽에서 오른쪽 순서로 tokenization을 진행한다. 각각의 token은 아래의 주의사항을 거치게 된다. 1. don't 같은 경우엔 whitespace가 없지만 do, n't로 토큰화 해야 하며, U.K 같은 경우에는 하나의 토큰으로 인식해야 한다. 2. prefix, suffix, infix를 분리할 수 있는지 여부.. 아래의 그림 형태라고 생각하면 될 듯 하다. 각각의 언어마다 tokenization을 할 때 주의해야 할 특별한 규칙들이 있을 수가 있으며 spaCy에서는 이러한 규칙들을 추가할 수가 있다. 하다보니 궁금한 사항이 생겼는데.. 규칙 지우는건 어떻.. 2018. 4. 19. spaCy 사용하기 - Named Entities spaCy를 사용해서 다양한 형태의 entity들을 식별해 볼 수가 있다. entity를 document 레벨이 아닌 token 레벨로도 접근 할 수가 있다. 위의 결과 값에서 B는 entity의 시작을 나타내고 O는 entitiy의 바깥, I는 entity 내부를 나타낸다. entity 정의가 되어 있지 않을 때는 새롭게 등록해 줄 수도 있다.(쓰다 보니 예제가.... -_-;; 따로 정치색이 있는 것은 아니고 아시는 분이 동명이인이라 놀리는 차원에서 쓴 예제예요.. 문제가 된다면 삭제하겠습니다..) 그런데 위와 같이 하면 기존의 entity가 사라지는 문제가 발생한다. 기존의 entity 정보가 손실되지 않게 하기 위해 아래와 같이 append를 시키자. NER을 training 하고 model up.. 2018. 4. 18. spaCy 사용하기 - 설치 및 dependency parser 사용 spaCy 설치는 정말 간단하다. (ubuntu 기준) 아래와 같이 pip install 로 설치해 주면 된다. $> pip install -U spacy spaCy를 설치한 후에는 언어에 맞는 모델도 설치를 해야 한다. (tokenizing, parsing, pos tagging 등을 하기 위한 모델) spaCy에서는 총 8가지 언어를 지원하며 (한국어는 지원 안함) 지원 언어는 아래와 같다. 각 언어별 모델 설치는 아래와 같이 진행하면 된다. python -m spacy download enpython -m spacy downlonad depython -m spacy download espython -m spacy downlonad ptpython -m spacy download frpython -m.. 2018. 4. 16. spaCy 사용하기 - nltk와 spaCy 비교 spaCy(https://spacy.io/)라고 nlp를 쉽게 할 수 있도록 도와주는 python package를 사용해 보고자 한다. python에 nltk가 있는데 굳이 spaCy를 써야하는 이유가 있나?? NLTK와 spaCy를 비교해 놓은 글이 있어서 링크와 함께 간단히 두 패키지의 특징을 비교해 보고자 한다. https://blog.thedataincubator.com/2016/04/nltk-vs-spacy-natural-language-processing-in-python/ 1. library 지원nltk의 경우 9개의 stemming library를 가지고 있으며(http://www.nltk.org/api/nltk.stem.html) 연구자 입장에서는 이들을 적절히 customizing 함으.. 2018. 4. 16. 이전 1 2 다음