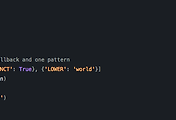
우리가 spaCy를 사용하기 위해 nlp 객체에 text 파라미터를 입력하면 결과적으로 아래와 같은 pipeline이 실행 된다.

아래와 같이 model을 호출하면, spaCy에서는 처음에 model의 meta.json을 읽는다. meta.json에는 model name과 language, description pipeline이 json 포멧으로 나타나 있다.
nlp = spacy.load('en')
{
"name": "model_name",
"lang": "en",
"description": "model description",
"pipeline": ["tagger", "parser"]
}
spaCy에서는 model.json에 나타난 pipeline을 읽고 해당 pipeline을 처리한 후 결과 Doc 객체를 리턴하게 된다.
또한 불필요한 pipeline을 disable 시킬 수도 있다.
nlp = spacy.load('en', disable=['parser', 'tagger'])
nlp = English().from_disk('/model', disable=['ner'])
model 로드 시점이 아니더라도 아래와 같이 pipeline을 삭제하거나 대체 시킬 수가 있다.
nlp.remove_pipe('parser')
nlp.rename_pipe('ner', 'entityrecognizer')
nlp.replace_pipe('tagger', my_custom_tagger)
custom pipeline을 만들고 이것을 spaCy에 추가할 수도 있다.

하지만 위의 코드 방식 보다는 아래의 코드 방식으로 코드를 작성하는 것을 장려한다.

spaCy 2.0 부터는 Doc, Span, Token에 대한 확장이 가능하다.
일단 attribute 확장이 가능해졌다.
from spacy.tokens import Doc, Span, Token
Doc.set_extension("hello", default=True)
doc._.hello
property 등록도 가능해졌으며, 함수 등록도 가능하다.

아래 코드는 parser 이전에 custom pipeline을 등록시키는 예제 코드이다.

사용자 정의 속성을 추가하는 것 이외에도 기존의 함수를 hooking 하는 기능도 제공한다. (override 기능과 비슷한 것 같음)