2019. 6. 7. 21:00ㆍmachine learning
텐서플로우로 만든 모델을 저장 및 로딩하고 모델 파라미터 값들을 tensorboard에 표현해 보자.
data = np.loadtxt('../data/data.csv', delimiter=',', unpack=True, dtype='float32')
x_data = np.transpose(data[0:2])
y_data = np.transpose(data[2:])
data.csv 파일을 읽어서 앞의 두개의 데이터는 x_data로 나머지 데이터는 y_data에 저장하자.
참고로 data.csv는 아래의 형태로 구성되어 있다.
1 0 0 0 1
1 1 0 1 0
0 0 1 0 0
x_data의 경우 transpose를 안해줄 경우 2x3 형태의 데이터 [[1 1 0] [0 1 0]] 로 저장이 되기 때문에 transpose를 해서 [[1 0],[1 1],[0 0]] 형태로 바꿔주자. (y_data도 마찬가지)
global_step = tf.Variable(0, trainable=False, name='global_step')
X = tf.placeholder(tf.float32)
Y = tf.placeholder(tf.float32)
with tf.name_scope('layer1'):
W1 = tf.Variable(tf.random_uniform([2, 10], -1., 1.), name='W1')
L1 = tf.nn.relu(tf.matmul(X, W1))
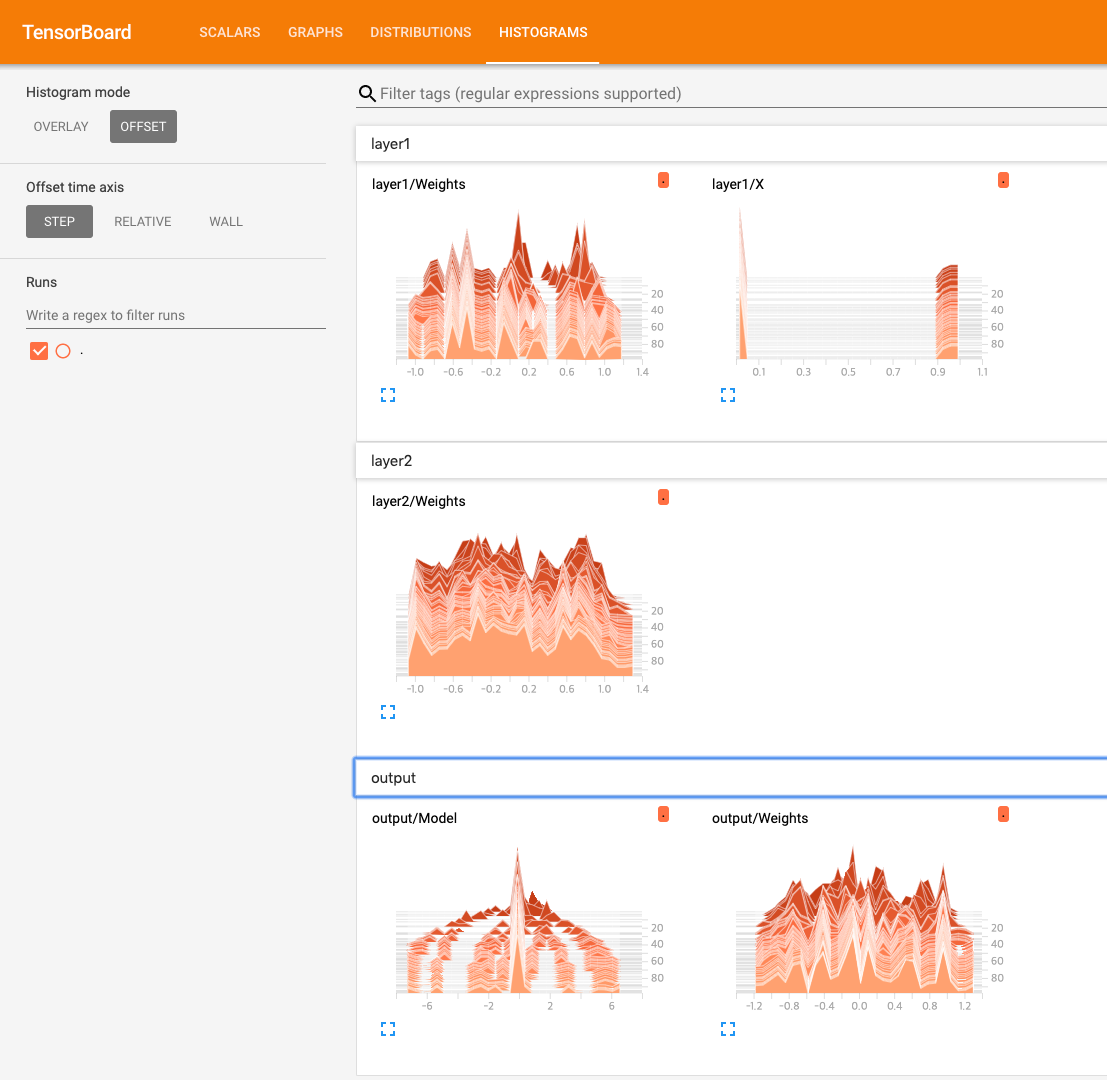
tf.summary.histogram("X", X)
tf.summary.histogram("Weights", W1)
with tf.name_scope('layer2'):
W2 = tf.Variable(tf.random_uniform([10, 20], -1., 1.), name='W2')
L2 = tf.nn.relu(tf.matmul(L1, W2))
tf.summary.histogram("Weights", W2)
with tf.name_scope('output'):
W3 = tf.Variable(tf.random_uniform([20, 3], -1., 1.), name='W3')
model = tf.matmul(L2, W3)
tf.summary.histogram("Weights", W3)
tf.summary.histogram("Model", model)
with tf.name_scope('optimizer'):
cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits_v2(labels=Y, logits=model))
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
train_op = optimizer.minimize(cost, global_step=global_step)
tf.summary.scalar('cost', cost)
global_step은 tf 내에서 사용되는 count 변수를 의미한다. 초기화만 해주면 내부적으로 1번의 optimizer를 수행할 때마다 1씩 count를 증가시킨다. tensorboard의 step을 찍기 위한 용도로 많이 사용된다. global_step은 학습에 전혀 관여하지 않는 변수이기 때문에 trainable은 False로 지정했다.
이번 코드에서는 각 레이어에 name_scope를 지정해줬다. 이렇게 name_scope를 지정해주면 tensorboard에서 보다 명확히 layer 계층을 확인해 볼 수가 있다.
현재 layer는 layer1->layer2->output->optimizer 이렇게 수행이 된다.
layer1에서는 [2x10]의 정규분포 난수를 가지는 W1을 가지고 있으며, input data와 행렬곱을 실행한다. (input : [1x2])
특이한 것은 tf.summary.histogram 이라는 함수이다. 해당 함수에 x data와 w data를 input으로 넣어주고 있다.
이런 식으로 tf.summary에 보고자 하는 type [histogram, scalar] 을 지정해 주고 값을 넣어주면 나중에 tensorboard를 통해 해당 값들을 확인해 볼 수가 있다.
layer2에서는 [10x20]의 정규분포 난수를 가지는 W2를 가지고 있고, W2는 layer1에서의 output(1x10)과 행렬곱을 실행한다. 여기서도 W2의 값이 tf.summary.histogram에 저장이 된다.
output layer에서는 [20x3]의 W3이 정의되고, W3과 layer2에서의 output(1x20)과 행렬곱을 실행한다. W3 값, layer2의 output과 W3의 행렬곱 결과 값을 각각 histogram에 저장한다.
마지막 optimizer에서는 Y값과 model 예측값의 cross_entropy를 구해서 cost 함수로 정의한다.
adamOptimizer를 실행하고, 마지막으로 cost 값을 scalar 형태로 tf.summary에 저장한다.
sess = tf.Session()
saver = tf.train.Saver(tf.global_variables())
ckpt = tf.train.get_checkpoint_state('../model/chapter5/model')
if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):
saver.restore(sess, ckpt.model_checkpoint_path)
else:
sess.run(tf.global_variables_initializer())
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter('./logs', sess.graph)
for step in range(100):
sess.run(train_op, feed_dict={X: x_data, Y: y_data})
print('Step: %d, ' % sess.run(global_step), 'Cost: %.3f' % sess.run(cost, feed_dict={X: x_data, Y: y_data}))
summary = sess.run(merged, feed_dict={X: x_data, Y: y_data})
writer.add_summary(summary, global_step=sess.run(global_step))
saver.save(sess, '../model/chapter5/dnn.ckpt', global_step=global_step)
모델 구현으 끝났으면 이제 학습을 진행해보자.
Session을 생성하고, saver 객체도 생성을 한다.
해당 위치의 model의 check point를 읽어서, 만약에 존재한다면, saver를 restore 시킨다. restore 시키게 되면 global_variables들이 이전에 학습하고 저장된 결과값으로 복원이 된다.
만약 해당 check point가 없거나 model이 없다면 global_variable을 초기화 시킨다. (아무것도 없으니깐 ..)
그런 다음 merged라는 summary에 저장했었던 변수 값들을 합치는 동작을 하는 함수를 정의하고, tf.summary.FileWriter 객체를 생성한다.
훈련을 돌리면서 merged 함수를 실행을 하고, 결과 값을 summary에 받는다. summary 값을 writer 객체에 추가함으로써 tensorboard 용 log date를 완성시킨다.
모든 훈련이 끝나면 최종 결과 모델을 saver에 저장한다.
아래는 위에서 summary에 저장했었던 scalar와 histogram을 tensorboard를 통해 본 결과이다. 참고로 tensorboard는 아래와 같은 명령을 사용해서 실행한다.
tensorboard --logdir [path] --port [port]

아래는 tensorboard를 통해 layer를 graph 형태로 본 결과이다.
