2017. 5. 23. 09:21ㆍmachine learning
doc2vec 방식이 생각보다 정말 간단해서 word2vec open source에 doc2vec 기능을 넣어보기로 했다.
우선 간략하게 doc2vec 방식을 설명하자면 아래의 그림과 같다. (DM 방식과 DBOW 방식이 있는데 일단 DM만 구현하기로 함..)
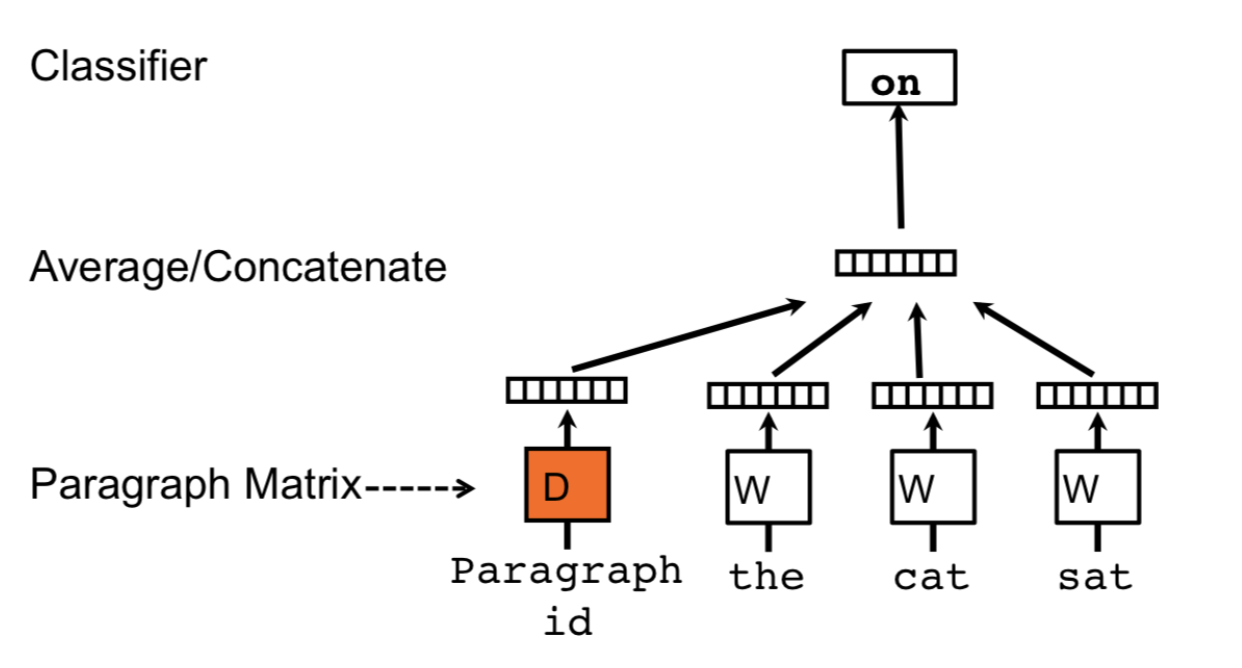
DM은 distributed memory 방식이라고 해서 word 들을 학습할 때 각각의 학습 단계를 vector에 기억시키고 학습된 최종 vector를 해당 document의 vector라고 정의하는 방식이다.
구현은 정말 간단하다. 기존 존재하던 word2vec 코드에 paragraph 용 벡터 메모리를 하나 추가로 할당해준다.
for(i = 0; i < (unsigned int)doc_count; i++){
for(j = 0; j < (unsigned int)vec_dim; j++){
next_random = next_random * (unsigned int)1103515245 + 12345;
p_out_vec[i][j] = (((next_random & 0xFFFF) / (double)65536) - 0.5) / vec_dim;
}
}
그런 후 training 단계에서 입력벡터에 추가로 document vector를 더해준 후 나눠준다.
for(c = 0; c < (unsigned int)m_vec_dim; c++){
m_p_neu1[c] += out_vec[doc_index][c];
}
cw++;
for (c = 0; c < (unsigned int)m_vec_dim; c++) {
m_p_neu1[c] /= cw;
}
마지막으로 학습한 결과만큼의 loss를 update 해준다.
for (c = 0; c < (unsigned int)m_vec_dim; c++) {
m_p_syn0[c + last_word * m_vec_dim] += m_p_neu1e[c];
out_vec[doc_index][c] += m_p_neu1e[c];
}
여기서 반전이 발생하는데, document vector를 만들고 cosine similarity로 유사도를 판별해서 문서 분류를 진행했는데 결과가 상당히 안좋게 나타났다.
내가 알고리즘을 잘못 이해했나 하는 생각에 tensorflow korea에 여러 자문을 구한 결과 doc2vec 성능이 그리 좋지 못하다는 결과를 얻었다. (gensim doc2vec은 잘되던데 -_-???)
성능을 높일 수 있는 많은 방법을을 제시해 주셨는데,
1. word2vec을 먼저 학습 한 후 doc2vec을 만들어 볼 것.
2. DM과 DBOW로 각각 document vector를 만든 후 concatenate 해라.
3. doc2vec 방식 보다는 wordembedding 한 결과에 tf/idf 가중치를 곱한 후 평균을 내라.
4. tf/idf 방식이 아닌 PCA로 가중치를 줘라.(https://arxiv.org/pdf/1704.05358.pdf) 이 경우에는 glove 가 더 좋은 성능을 낸다.
문서 분류를 위해 우선 가장 그럴듯해 보이는 3번 방식부터 해봐야 겠다.