2021. 12. 20. 20:20ㆍServer/Ubuntu
원문 주소 : https://kinvolk.io/blog/2020/12/improving-kubernetes-and-container-security-with-user-namespaces/
Kinvolk: Improving Kubernetes and container security with user namespaces
Improving Kubernetes and container security with user namespaces
kinvolk.io
What are user namespaces?
Linux 상의 컨테이너는 네임스페이스, cgroup 그리고 다른 linux 기본 요소를 기반으로 한다. Linux API는 다양한 종류의 네임스페이스들을 제공하며 해당 네임스페이스들은 각각 os 시스템의 특정 영역을 독립적으로 만든다. 예를 들어 다른 네트워크 네임스페이스에 있는 두 개의 컨테이너는 서로 각각의 네트워크 인터페이스를 볼 수 없다. 서로 다른 pid 네임스페이스에 있는 두 개의 컨테이너도 각각의 프로세스들을 볼 수 없다.
User 네임스페이스도 이와 비슷하다 : 사용자 ID와 그룹 ID를 분리한다. Linux 상에서 모든 파일들과 모든 프로세스들은 일반적으로 /etc/passwd, /etc/group에 정의된 특정 사용자 id 및 그룹 id에 의해서 소유가 정해진다. 컨테이너는 호스트의 사용자 ID와 그룹 ID의 하위 집합만 볼 수 있도록 user 네임스페이스를 구성할 수 있다. 아래의 그림을 보면 두 개의 컨테이너는 컨테이너와 호스트 사이가 분리될 수 있도록 고유한 사용자 ID를 사용하도록 구성된다. 컨테이너 1에 있는 프로세스들과 파일들은 루트(user id 0)인 것처럼 보이지만 실제로는 호스트에서 사용자 ID(100000)을 사용하고 있다.
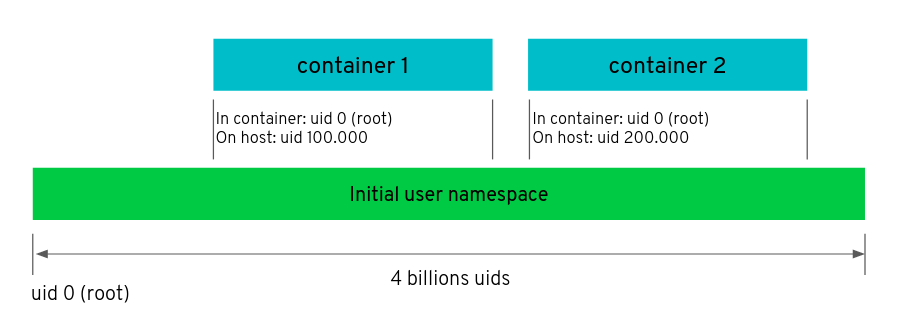
User namespaces and capabilities
컨테이서에서 사용자 "root"로써 나타나 보이지만 실제로는 다른 사용자인 것은 user 네임스페이스에서 중요한 특징이다.
- Linux 2.2 이전에는 사용자 ID가 0인 "root" 사용자가 네트워크 구성 및 새로운 파일 시스템 마운팅 같은 권한 있는 작업을 수행 할 수 있었다. 일반 사용자는 이러한 권한 작업은 수행할 수 없다.
- Linux 2.2 부터 "root" 사용자의 권한은 다른 기능으로 분리가 된다. ex) CAP_NET_ADMIN은 네트워크를 구성하고, CAP_SYS_ADMIN은 새로운 파일 시스템을 마운트한다.
- Linux 3.8은 2013년에 user 네임스페이스를 도입했고, 이에 따라 권한은 더이상 전역적이지 않고 user 네임스페이스 내에서 해석이 된다.
이것이 의미하는 바를 설명하기 위해 다음과 같은 예를 들어 보자. 컨테이너가 ssh 파일시스템을 마운트하기 위해 "sshfs" 프로그램을 실행하는 시나리오를 고려해 보자. 파일시스템을 마운트하기 위해서는 CAP_SYS_ADMIN 기능이 필요하다. 이것은 컨테이너에 너무 많은 권한을 부여하고, 호스트와 컨테이너 간의 분리를 무효화하므로 일반적으로 컨테이너에 해당 기능을 부여하지 않는다.
컨테이너가 새로운 user 네임스페이스 없이 설정될 때, "sshfs"를 성공적으로 실행할 수 있는 유일한 방법은 컨테이너에 CAP_SYS_ADMIN을 제공하는 것이다.

하지만 컨테이너가 새로운 user 네임스페이스를 사용할 때, 호스트 user 네임스페이스 상에 CAP_SYS_ADMIN 없이도 해당 user 네임스페이스에 CAP_SYS_ADMIN을 부여할 수 있다. 실제 사용자 id는 호스트의 root가 아니기 때문에, 컨테이너에서 root(user id 0)이 되는 것은 호스트에 영향을 미치지 않는다.
보다 정확하게는 컨테이너의 마운트 네임스페이스의 파일시스템을 마운트 하기 위해 해당 마운트 네임스페이스를 소유하고 있는 user 네임스페이스 내에 CAP_SYS_ADMIN을 가지는 프로세스가 요구된다.
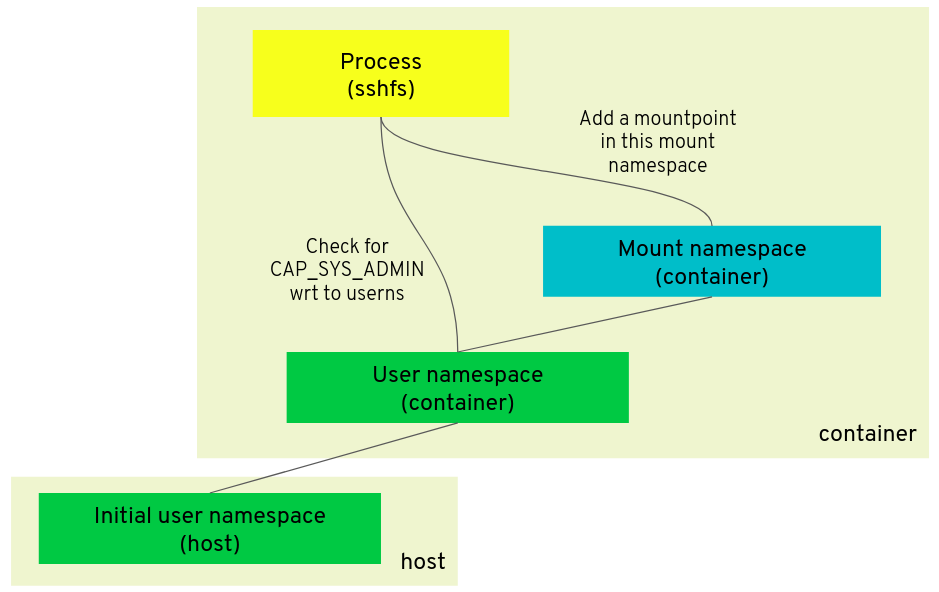
User namespaces and filesystems
위에서 설명한 대로 user 네임스페이스의 기능으로 인해 호스트의 root가 아니어도 컨테이너가 파일 시스템을 마운트 할 수 있는 것처럼 보인다. 그러나 파일시스템에 따라 더 많은 부분이 동작한다. Linux는 FS_USERNS_MOUNT flag로 표시된 user 네임스페이스에 마운팅하기에 안전한 파일 시스템 목록을 유지한다. non-initial user 네임스페이스 내에 새로운 마운트를 생성하는 것은 오직 해당 파일 시스템에서만 해당한다. 아래 명령어를 통해 Linux git 저장소에서 목록을 찾을 수 있다.
git grep -nw FS_USERNS_MOUNT
아래 표에서 볼 수 있듯이 non-initial user 네임스페이스의 새로운 파일시스템 마운트는 처음에는 오직 procfs와 sysfs로만 제한되었으며, 이후에는 권한이 없는 사용자가 파일시스템을 안전하게 사용할 수 있는지 확인하는데 시간이 소요되기 때문에 user 네임스페이스에 마운트할 수 있는 파일시스템이 점점 더 많아졌다.

Impact on container security
User 네임스페이스는 호스트와 컨테이너를 분리시키는 또 다른 보안 계층이다. 여러 컨테이너 취약점 문제가 있었고, 이런한 취약점은 user 네임스페이스를 사용함으로써 많이 완화되었다.
예를 들어 컨테이너에서 호스트 runc 바이너리를 덮어쓸 수 있는 CVE-2019-5736(fix in runc) 문제가 있었다. 취약점 발표에서는 user 네임스페이스를 사용하는 것이 완화 방법이라고 언급했다.
이것은 취약점에 의해 컨테이너의 프로세스가 /proc/self/exe를 경유해서 호스트의 runc를 참조하더라도, runc 바이너리는 컨테이너에 매핑되지 않은 user(root)에 의해 소유되기 때문이다. 컨테이너는 runc를 특별한 사용자 "nobody"가 소유한 것으로 인식하고, 컨테이너의 "root" 사용자는 쓰기 권한을 가지지 못하도록 한다.
아래의 다이어그램은 runc가 컨테이너를 생성하는 데 사용되는 순서를 보여주고 있으며, 어떻게 /proc/self/exe 가 runc에 참조될 수 있는지를 보여준다.

쿠버네티스 User 네임스페이스 KEP(KEP/127)은 user 네임스페이스에 의해 완화될 수 있는 몇 가지 다른 취약점 리스트를 보여준다.
Enabling user namespaces for FUSE filesystems
Linux 4.18 이전에는 FUSE가 user 네임스페이스에서 허용되지 않았으며, 허용하기 위한 많은 노력이 있었다 : 우분투 커널은 이미 이를 지원하기 위해 패치되었다.
Linux upstream에서 누락된 부분은 integrity subsystem인 IMA(Integrity Measurement Architecture)와의 적절한 통합이었다. IMA를 사용하는 Linux 시스템 상에서 커널은 프로세스가 파일을 읽거나 실행하기 전에 파일이 수정되었는지를 감지한다. 또한 실행된 상태에 대한 추적을 가능하게 해준다. 또한 내용이 양호하거나 신뢰된 암호키로 사인된 경우에만 프로그램이 실행될 수 있도록 EVM(Extended Verification Module)을 활성화 하는게 가능하다.
전통적인 파일시스템에서의 로컬 하드 디스크에 저장된 파일들과 달리 FUSE와 같은 파일시스템 상의 파일들은 커널의 재측정, 재평가, 재감사 없이 수정할 수 있다.
이 시나리오에서 다음의 문제를 보여주기 위해 memfs FUSE 드라이버를 패치했다.
1. 첫번째 request에서, FUSE 드리아버는 초기 내용과 함께 파일을 제공한다.
2. IMA가 파일의 측정을 제공한다.
3. 두번째 request에서 FUSE 드라이버가 변경된 내용의 동일한 파일을 제공한다.
4. IMA는 다시 측정하지 않으며, 변경된 콘텐츠는 측정되지 않는다.
당시 IMA가 항상 파일을 재측정, 재평가, 재감사하도록 하는 IMA의 강제 옵션으로 문제 해결을 시도했다. 우리는 해당 옵션을 테스트 했다.
첫번째 옵션은 FUSE 파일시스템을 특별한 것으로 인식하고, 강제 옵션을 사용하여 커널이 변경 사항을 감지하지 못한 경우에도 각 요청에 대해 측정이 수행되도록 했다. 이 옵션을 사용하면 IMA는 모든 파일시스템의 동작에 대해 알아야 하며, 이러한 지식을 잘못된 계층에 전달한다.
이러한 문제를 풀기 위한 두 번째 옵션으로 파일 시스템이 캐싱과 관련된 동작을 IMA 하위 시스템에 전달할 수 있도록 하는 새로운 파일시스템 플래그 FS_NO_IMA_CACHE(v1,v2,v3,v4)를 도입했다. IMA 하위 시스템은 플래그를 확인하고 플래그가 있는 경우에만 강제 옵션을 사용할 수 있다. 이런 식으로 하면 IMA 하위 시스템은 다른 파일시스템에 대해 알 필요가 없다.
하지만 IMA 강제 옵션은 모든 이슈를 해결하지 못했으며, 서명을 여전히 의미있게 검증하지 못했다. 결국 Linux 4.17 버전에 다음의 해결책이 구현되었다.
- 파일시스템이 서명을 검증할 수 없다는 것을 IMA에게 알릴 수 있도록 하는 새로운 플래그 SB_I_IMA_UNVERIFIABLE_SIGNATURE를 추가한다. 오직 FUSE 파일시스템에만 이 플래그를 사용한다. 좀 더 보안을 강화하기 위해 IMA 사용자들은 user 네임스페이스가 없어도 FUSE 파일시스템에서 IMA 서명 확인을 실패하게 하는 IMA 정책 "fail_securely"를 사용할 수 있다.
- 파일 시스템이 신뢰할 수 없는 user 네임스페이스에 마운트 될 때, 사용할 수 있는 새로운 플래그 SB_I_UNTRUSTED_MOUNTER를 추가한다. 이 경우 IMA 측정이 실패한다.
Linux 4.17에서의 IMA fix 이후에 non-initial user 네임스페이스의 FUSE 파일시스템은 Linux 4.18에서 허용이 됐다.
Bring user namespaces to Kubernetes
runc와 같은 OCI 컨테이너 런타임에서는 user 네임스페이스가 지원되지만 쿠버네티스에서는 이 기능을 사용할 수 없다. user 네임스페이스를 추가하려는 쿠버네티스의 지속적인 노력은 2016년부터 시작됐다.
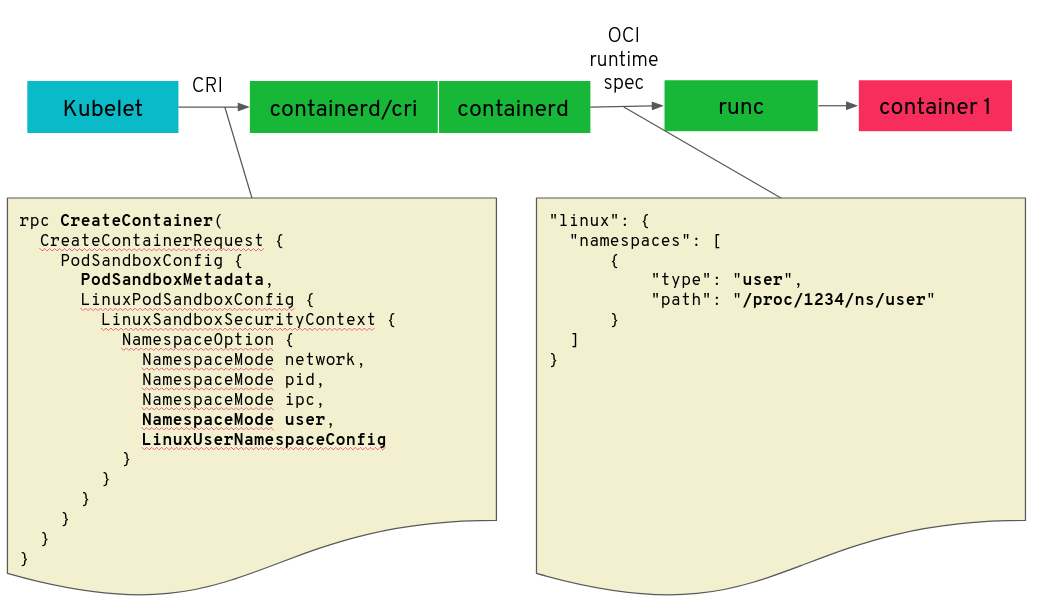
첫 번째 시도에서 쿠버네티스는 이미 CRI(Container Runtime Interface)를 도입했지만, 아직 기본값은 아니었다. 하지만 요즘 kubelet은 CRI은 gRPC 인터페이스를 통해 컨테이너 런타임과 통신하였고, user 네임스페이스에 대한 지원을 도입하는 주요 대상이 되었다.

위의 다이어그램은 kubelet이 컨테이너 런타임과 통신하는 각각의 구조를 보여준다.
1. 예전 방식 : kubelet은 Docker API를 사용하여 컨테이너를 시작하기 위해 docker와 직접 통신한다.(deprecated)
2. 새로운 방식 : kubelet은 CRI의 gRPC 인터페이스를 통해 컨테이너 런타임과 통신한다. 컨테이너 런타임에는 CRI 프로토콜을 이해하는 구성 요소인 "CRI shim"가 있을 수 있다.
3. containerd를 컨테이너 런타임으로 사용할 때의 새로운 방법 : containerd는 CRI 프로토콜을 이해하기 위해 containerd/cri로 컴파일 된다. kubelet으로부터 CRI 명령어를 수신하고 runc와 OCI 런타임을 사용하여 컨테이너를 시작한다.
CRI changes for user namespaces
user 네임스페이스를 지원하기 위한 CRI의 정확한 변경 사항은 아직 논의 중이다. 하지만 일반적인 아이디어는 다음과 같다.
1. kubelet은 컨테이너 런타임에 RunPodSandbox() 함수를 호출해서 pod sandbox를 시작하도록 요청한다. 이렇게 하면 pod의 서로 다른 컨테이너들 사이에서 공유된 네임스페이스를 가질 수 있는 "sandbox" 컨테이너("infrastructure" 컨테이너라고 불리기도 함) 가 생성될 것이다. runc에서 제공된 OCI 런타임에서도 볼 수 있듯이, user 네임스페이스는 이 단계에서 특정 uid와 gid로 매핑될 것이다.

2. 그런 다음 kubelet은 이전에 생성된 sandbox에 대한 참조와 함께 pod의 각 컨테이너를 생성하기 위해 CreateContainer() 함수를 호출할 것이다. OCI 런타임 configuration은 sandbox의 user 네임스페이스를 재사용하도록 명시할 것이다.
이러한 방식으로 user 네임스페이스는 pod의 다른 컨테이너에서 공유된다.
IPC 및 네트워크 네임스페이스 역시도 pod 레벨에서 공유 되며, IPC 매커니즘과 network loopback 인터페이스를 사용해서 서로 다른 컨테이너에서도 통신이 가능하게 허용해 준다. IPC 네트워크와 네트워크 네임스페이스는 pod의 user 네임스페이스에 의해 소유되므로, 해당 네임스페이스의 기능이 pod 내에서는 유효하지만 호스트에서는 적용되지 않는다. 예를 들어 컨테이너에서 user 네임스페이스 내에 CAP_NET_ADMIN이 지정되었다면, 호스트가 아니라 pod의 네트워크에서 구성할 수 있도록 허용한다. 만약 컨테이너에 CAP_IPC_OWNER가 지정되었다면, 호스트가 아니라 pod의 IPC 객체의 권한을 무시할 수 있다.
각 컨테이너의 마운트 네임스페이스 역시 pod의 user 네임스페이스에 의해 소유된다. 따라서 컨테이너에 CAP_SYS_ADMIN이 주어졌다면, 해당 마운트 네임스페이스에서 마운트를 수행할 수 있지만 호스트 마운트 네임스페이스에는 적용이 되지 않는다.

Kubernetes volumes
쿠버네티스의 user 네임스페이스에 대한 가장 큰 과제는 볼륨 지원이다.
아래의 시나리오를 살펴보자.
1. 컨테이너 1은 NFS에 파일을 쓴다. 파일은 컨테이너에 매핑된 사용자이기 때문에 사용자 ID 100000에 속한다.
2. 컨테이너 2는 NFS에서 파일을 읽는다. 컨테이너 2에는 사용자 ID 100000가 매핑되어 있지 않기 때문에, 파일은 특수 코드인 "nobody"가 되며 pseudo 사용자 id 65534에 속한다. 파일 접근 권한 문제가 발생 될 수 있다.

이 문제를 해결하기 위한 다양한 방법이 존재한다.
1. 모든 pod에 대해 동일한 사용자 id를 사용한다. 이렇게 하면 컨테이너 간의 isolation이 줄어들지만, user 네임스페이스 없는 상태보다는 훨씬 나은 보안을 제공한다. 볼륨의 파일들은 100000과 같은 사용자 id가 소유하고 관리자는 쿠버네티스 configuration 상에서 사용자 ID가 변경되지 않도록 사용자 id 매핑을 관리할 필요가 있다.
2. 각 pod에 대해 다른 사용자 id를 사용하지만 추가 매커니즘을 사용해서 사용자 id를 변경한다. shiftfs, fsid mappings 또는 Linux 커널내의 new mount API 등과 같이 다양한 커널 매커니즘이 제공된다. 하지만 지금까지 이러한 솔루션 중 어떤 것도 Linux 업스트림을 위해 준비되어 있지는 않다.
우리의 현재 제안은 첫번째 가능성을 사용할 수 있도록 하고, 더 나은 솔루션이 나오면 확장이 가능하도록 하는 것이다.
Conclusion
user 네임스페이스는 컨테이너에 추가 보안 계층을 제공하는데 유용한 Linux 기본 요소이다. 이는 과거 여러 취약점으로부터 유용하다는 것이 증명되었다. 비록 볼륨 지원과 함께 몇몇의 단점이 존재하지만 Linux 커널 개발은 해당 영역에서 활발히 진행되고 있다.
일단 쿠버네티스에서 user 네임스페이스에 대한 지원이 완료된다면, 쿠버네티스는 컨테이너 워크로드와 Linux 호스트 사이에서 더 나은 보안 isolation을 얻게 될 것이다. 또한 더 많은 권한을 바탕으로 동작되는 컨테이너의 새로운 사례들을 얻게 될 것이다. user 네임스페이스의 지원 없이 무엇을 하기에는 너무나도 위험한 작업이다.