2022. 12. 29. 15:40ㆍmachine learning
kubeflow를 통해 모델 생성을 위한 pipeline을 작성하고 작성된 모델을 kfserving을 통해 serving을 해볼 수가 있다. 오늘은 그 작업을 해보려고 한다.
우선 pipeline을 작업하기 위해서는 아래와 같은 requirements 가 필요하다.
kfp == 1.8.9
scikit-learn == 1.0.1
dill == 0.3.4
numpy
kfserving
위 python package를 설치했다면 이제 pipeline을 위한 코드를 작성해보자.
pipeline.py
import kfp
from kfp import onprem
from kfp import dsl
def preprocess_op():
return dsl.ContainerOp(
name='Preprocess Data',
image='kubeflow:preprocess_0.15',
arguments=['--data-path', '/pipeline'],
file_outputs={
'x_train': '/pipeline/preprocess/x_train.npy',
'x_test': '/pipeline/preprocess/x_test.npy',
'y_train': '/pipeline/preprocess/y_train.npy',
'y_test': '/pipeline/preprocess/y_test.npy'
}
).apply(onprem.mount_pvc(pvc_name='pvc', volume_name='pipeline', volume_mount_path="/pipeline"))
def train_op(x_train, y_train):
return dsl.ContainerOp(
name='Train Model',
image='kubeflow:train_0.12',
arguments=[
'--x_train', x_train,
'--y_train', y_train,
'--model_path', '/pipeline/model'
],
file_outputs={
'model': '/pipeline/model/model.joblib'
}
).apply(onprem.mount_pvc(pvc_name='pvc', volume_name='pipeline', volume_mount_path="/pipeline"))
def test_op(x_test, y_test, model):
return dsl.ContainerOp(
name='Test Model',
image='kubeflow:test_0.10',
arguments=[
'--x_test', x_test,
'--y_test', y_test,
'--model', model
],
file_outputs={
'mean_squared_error': '/app/output.txt'
}
).apply(onprem.mount_pvc(pvc_name='pvc', volume_name='pipeline', volume_mount_path="/pipeline"))
@dsl.pipeline(
name='pipeline',
description='test model.'
)
def boston_pipeline():
_preprocess_op = preprocess_op()
_train_op = train_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_train']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_train'])
).after(_preprocess_op)
_test_op = test_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_test']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_test']),
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_train_op)
import kfp.compiler as compiler
compiler.Compiler().compile(boston_pipeline, __file__ + ".tar.gz")
해당 pipeline은 preprocess -> train,test를 거치는 작업 코드이다. preprocess, train, test를 보면 각각이 실행되기 위한 docker image가 명시되어 있으며 각각의 docker image 내용은 아래와 같다.
preprocess dockerfile
FROM python:3.7-slim
RUN pip install -U joblib==1.0.1 numpy==1.21.2 scikit-learn==1.0.2
RUN mkdir -p /app
WORKDIR /app
COPY preprocess.py ./preprocess.py
ENTRYPOINT [ "python", "preprocess.py" ]
preprocess.py
from sklearn import datasets
from sklearn.model_selection import train_test_split
import os
import numpy as np
import argparse
def _preprocess_data(opt):
x, y = datasets.load_boston(return_X_y=True)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.33)
path = os.path.join(opt.data_path, 'preprocess')
if not os.path.isdir(path):
os.makedirs(path)
with open(os.path.join(path, 'x_train.npy'), 'wb') as f:
np.save(f, x_train)
with open(os.path.join(path, 'x_test.npy'), 'wb') as f:
np.save(f, x_test)
with open(os.path.join(path, 'y_train.npy'), 'wb') as f:
np.save(f, y_train)
with open(os.path.join(path, 'y_test.npy'), 'wb') as f:
np.save(f, y_test)
if __name__ == '__main__':
print('Preprocessing data...')
parser = argparse.ArgumentParser()
parser.add_argument('--data-path', type=str, help='dataset root path')
opt = parser.parse_args()
_preprocess_data(opt)
preprocess에서는 sklearn에서 제공하는 boston 집값 데이터를 받아서 각각 train, test 데이터로 나눈 후 /pvc/preprocess 위치에 각각의 train을 위한 데이터를 저장한다.
train dockerfile
FROM python:3.7-slim
WORKDIR /app
RUN pip install -U joblib==1.0.1 numpy==1.21.2 scikit-learn==1.0.2
COPY train.py ./train.py
ENTRYPOINT [ "python", "train.py" ]
train.py
import argparse
import joblib
import os
import numpy as np
from sklearn.linear_model import SGDRegressor
def train_model(x_train, y_train, model_path):
x_train_data = np.load(x_train)
y_train_data = np.load(y_train)
if not os.path.isdir(model_path):
os.makedirs(model_path)
model = SGDRegressor(verbose=1)
model.fit(x_train_data, y_train_data)
joblib.dump(model, os.path.join(model_path, 'model.joblib'))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_train')
parser.add_argument('--y_train')
parser.add_argument('--model_path')
args = parser.parse_args()
train_model(args.x_train, args.y_train, args.model_path)
train 데이터에서는 train과 train_label 데이터, 그리고 output 으로 출력될 model path를 파라미터로 전달 받는다. 전달 받은 값을 가지고 선형회귀 모델을 태운 후 그 결과 모델을 model path에 저장한다.
마지막으로 test 코드는 아래와 같다.
test dockerfile
FROM python:3.7-slim
WORKDIR /app
RUN pip install -U joblib==1.0.1 numpy==1.21.2 scikit-learn==1.0.2
COPY test.py ./test.py
ENTRYPOINT [ "python", "test.py" ]
test.py
import argparse
import joblib
import numpy as np
from sklearn.metrics import mean_squared_error
def test_model(x_test, y_test, model_path):
x_test_data = np.load(x_test)
y_test_data = np.load(y_test)
model = joblib.load(model_path)
y_pred = model.predict(x_test_data)
err = mean_squared_error(y_test_data, y_pred)
with open('output.txt', 'a') as f:
f.write(str(err))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_test')
parser.add_argument('--y_test')
parser.add_argument('--model')
args = parser.parse_args()
test_model(args.x_test, args.y_test, args.model)
test 코드에서는 preprocess로부터 test데이터를, train 작업으로부터 output model 경로를 받아온 후, 해당 model에 test 데이터를 실행시키고 로컬 위치에 mse 값을 저장하는 것으로 끝난다.
위와 같이 pipeline을 저장했다면 아래와 같이 이제 pipeline을 컴파일 하자.
$> python pipeline.py
위와 같이 실행하면 pipeline.py.tar.gz 파일이 생성된다. 이 파일을 kubeflow ui 상의 왼쪽 메뉴의 pipelines를 클릭한 후 오른쪽 상단의 upload pipelines를 클릭하자.
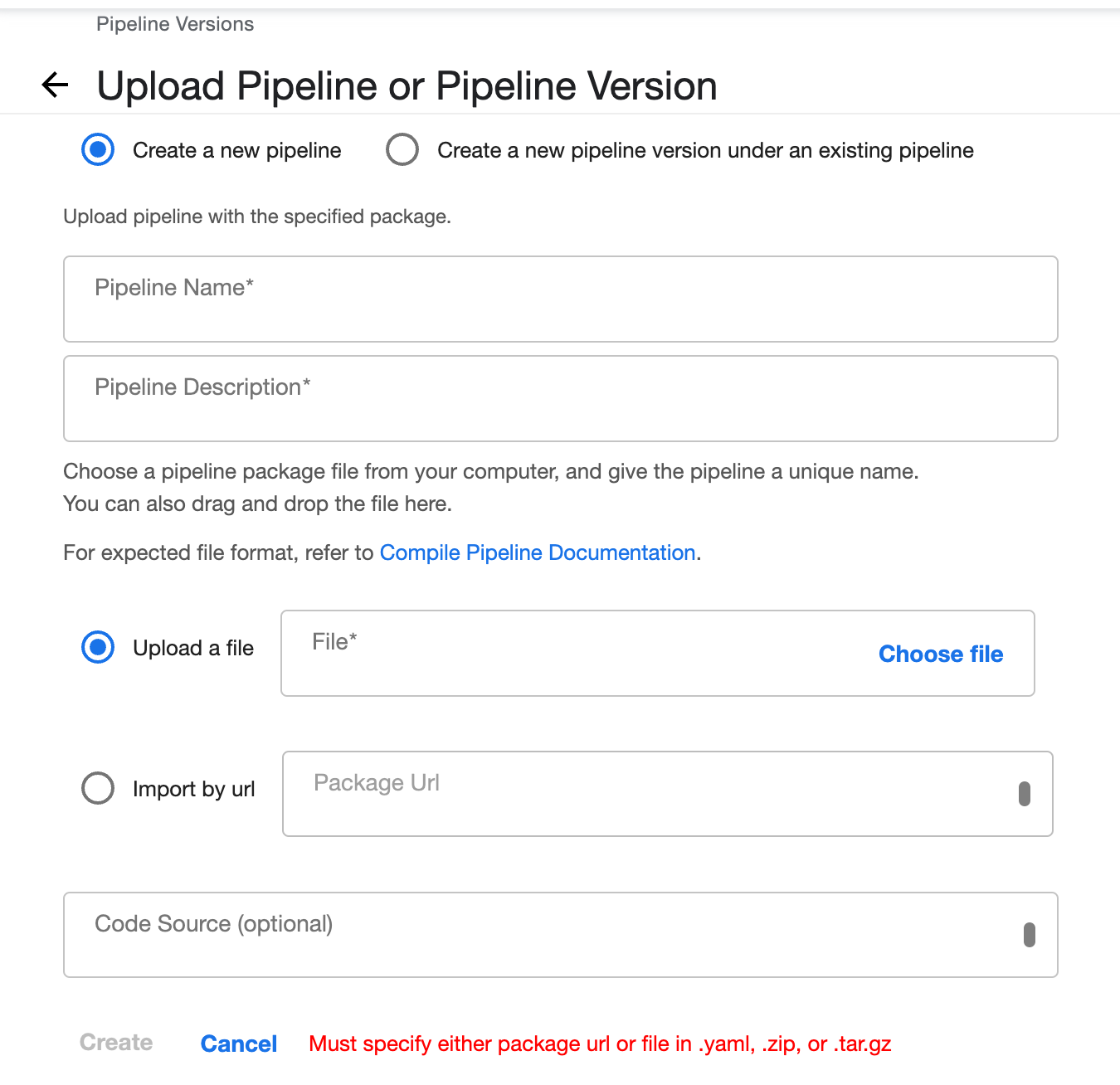
upload pipeline을 클릭하면 아래와 같은 화면이 나타나며, Upload a file에서 Choose file을 선택한 후 아까 컴파일 한 pipeline.py.tar.gz 파일을 업로드 한 후 create 하자.
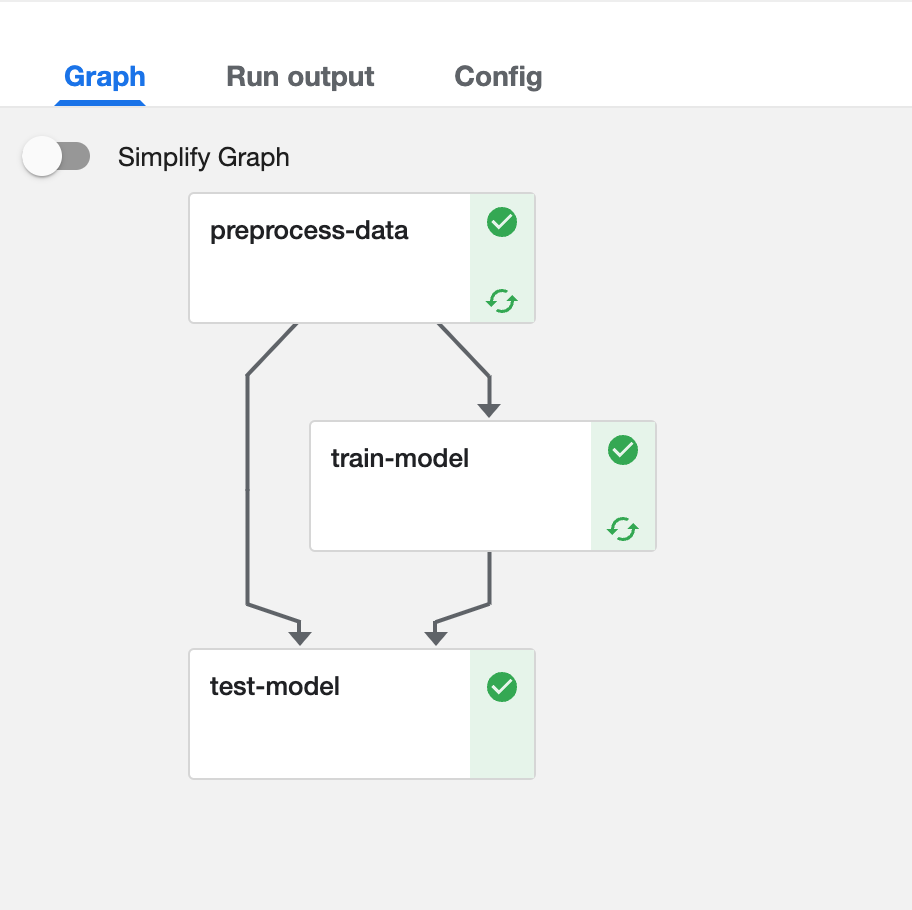
create를 하게 되면 diagram이 생성되는 것을 확인 할 수 있다. 다시 오른쪽 상단 메뉴에서 create run을 클릭한 후 run을 실행하자. experiment가 없는 경우 따로 experiment를 만들어 주어야 한다. 오른쪽 상단 메뉴에서 create experiment를 클릭 한 후 적절한 이름을 넣고 experiment를 create 하자.
이렇게 만들고 run을 돌리면 pipeline이 좌르르륵 돌아가는 것을 확인할 수가 있으며 성공 시 아래와 같은 화면을 만날 수 있다.