Char based Text to CNN 한글 적용하기
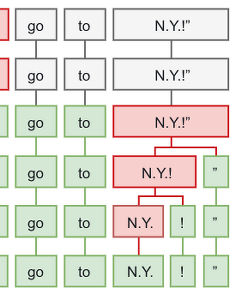
Text의 각 Character들을 (한글로 치면 하나의 음절) 하나의 특징데이터로 삼고 CNN을 이용해서 분류작업을 해보기로 했다. 기본 Text to CNN에 대한 간략한 설명. http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/ 대략적으로 설명하자면 각각의 text내의 word 들을 vector로 변환한 후 해당 vector 값들을 나열해서 2차원 이미지 배열 처럼 만든다. 예를들어 I like coffee 라는 text가 있다면 I, like, coffee 이 단어들을 각각 3차원 벡터로 변환을 하고 ([1,0,0], [0,1,0], [0,0,1]) 변환된 벡터를 나열하면 3 * 3의 행렬이 생성된다...
2018. 4. 10.
Char based Text to CNN 한글 적용하기
Text의 각 Character들을 (한글로 치면 하나의 음절) 하나의 특징데이터로 삼고 CNN을 이용해서 분류작업을 해보기로 했다. 기본 Text to CNN에 대한 간략한 설명. http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/ 대략적으로 설명하자면 각각의 text내의 word 들을 vector로 변환한 후 해당 vector 값들을 나열해서 2차원 이미지 배열 처럼 만든다. 예를들어 I like coffee 라는 text가 있다면 I, like, coffee 이 단어들을 각각 3차원 벡터로 변환을 하고 ([1,0,0], [0,1,0], [0,0,1]) 변환된 벡터를 나열하면 3 * 3의 행렬이 생성된다...
2018. 4. 10.
 [13강] scala 계층 구조
스칼라의 계층 구조는 아래의 트리 구조를 따른다. 최상위 슈퍼 클래스는 scala.Any이다. 모든 클래스가 Any를 상속하기 때문에 객체 간의 ==, !=, equals 등의 비교가 가능하다. 또한 Any 클래스에서는 == , !=는 final로 설정이 되어 있기 때문에 override가 불가능 하다. Any는 서브 클래스를 두 개 가지고 있는데 바로 AnyVal과 AnyRef이다. AnyVal의 경우는 Scala에 존재하는 값 클래스의 부모 클래스이며, Byte, Short, Char, Int, Float, Double, Boolean, Unit 이렇게 9 가지 클래스가 값 클래스에 해당한다.값 클래스는 내부적으로 final 클래스로 선언이 되었기 때문에 new 연산자로 인스턴스화가 불가능 하다.즉 ..
2018. 4. 3.
[13강] scala 계층 구조
스칼라의 계층 구조는 아래의 트리 구조를 따른다. 최상위 슈퍼 클래스는 scala.Any이다. 모든 클래스가 Any를 상속하기 때문에 객체 간의 ==, !=, equals 등의 비교가 가능하다. 또한 Any 클래스에서는 == , !=는 final로 설정이 되어 있기 때문에 override가 불가능 하다. Any는 서브 클래스를 두 개 가지고 있는데 바로 AnyVal과 AnyRef이다. AnyVal의 경우는 Scala에 존재하는 값 클래스의 부모 클래스이며, Byte, Short, Char, Int, Float, Double, Boolean, Unit 이렇게 9 가지 클래스가 값 클래스에 해당한다.값 클래스는 내부적으로 final 클래스로 선언이 되었기 때문에 new 연산자로 인스턴스화가 불가능 하다.즉 ..
2018. 4. 3.