2019. 6. 6. 16:53ㆍmachine learning
Word2Vec 모델을 deep learning을 이용해서 구현해 보자.
import tensorflow as tf
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
tensorflow와 matplotlib, numpy를 각각 import 한다. (각각 version : 1.13.0, 3.0.3, 1.16.3)
matplotlib는 단어 -> 벡터로 변환 후 2차원 그래프 상에서 표시해주기 위한 용도로 사용된다.
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="/usr/share/fonts/truetype/dejavu/gulim.ttf").get_name()
# matplot 에서 한글을 표시하기 위한 설정
matplotlib.rc('font', family=font_name)
간혹 matplot에서 한글을 표현할 때 깨지는 현상을 확인할 수가 있는데, 이는 해당 서버에 한글 폰트가 없어서 생기는 문제이다. 위의 코드와 같이 한글 포트를 지정해 주면 그래프에 한글이 나타나게 된다. 참고로 해당 서버에 어떤 폰트가 있는지 보기 위해서는 아래와 같이 호출해서 폰트 리스트를 가져오자.
font_manager.get_fontconfig_fonts()
matplot 한글 폰트 관련된 보다 자세한 포스팅은 아래의 글을 참조하자.
2016/10/19 - [machine learning] - Jupyter에서 Matplotlib 한글 적용하기
Jupyter에서 Matplotlib 한글 적용하기
word2vec을 통해 word 들을 vector로 변환하였고, 이를 그래프로 표현해주어야 한다. (word 간의 분포도를 보고 싶으니깐..) vector는 3차원만 넘어가도 표현하는데 어려움이 많다. 그래서 이를 위해 tsne라는 것..
yujuwon.tistory.com
# 단어 벡터를 분석해볼 임의의 문장들
sentences = ["나 고양이 좋다", "나 강아지 좋다", "나 동물 좋다", "강아지 고양이 동물", "여자친구 고양이 강아지 좋다", "고양이 생선 우유 좋다", "강아지 생선 싫다 우유 좋다", "강아지 고양이 눈 좋다", "나 여자친구 좋다", "여자친구 나 싫다", "여자친구 나 영화 책 음악 좋다", "나 게임 만화 애니 좋다", "고양이 강아지 싫다", "강아지 고양이 좋다"]
# 문장을 전부 합친 후 공백으로 단어들을 나누고 고유한 단어들로 리스트를 만듭니다.
word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
분석하고자 하는 문장 리스트는 sentences 변수에 담겨져 있다. 해당 문장들을 모두 합친 다음에 공백으로 분리하고 중복을 제거함으로써 unique한 단어 셋을 생성하자.
ex) ['싫다', '음악', '강아지', '고양이', '여자친구' ....]
word_dict = {w: i for i, w in enumerate(word_list)}
각 단어별로 index를 지정해 주자.
ex) {'싫다' : 0, '음악': 1, '강아지': 2, ....]
skip_grams = []
for i in range(1, len(word_sequence) - 1):
target = word_dict[word_sequence[i]]
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
for w in context:
skip_grams.append([target, w])
우리는 이제 윈도우 사이즈를 1로 하는 스킵그램 리스트를 만들 것이다. 스킵그램은 타겟 단어를 통해 해당 문장의 context를 예측하는 단어 모델을 말한다. ex) 게임이라는 단어 입력시 -> 나 게임 만화 애니 좋다. 라는 문장을 유추해 내야 한다.
여기서는 윈도우 사이즈를 1로 정했기 때문에 스킵그램, cbow등은 별차이가 없다고 봐야한다. 그냥 이런식으로 구현할 수 있구나 정도로 이해하자..
예를 들어 "나 게임 만화 애니 좋다" 라는 문장이 입력으로 들어오게 되면,
-> ([나, 만화], 게임), 나 혹은 만화라는 단어를 통해 게임이라는 단어를 유추해 낼 수가 있으며, ([나, 만화], 게임)을 풀어서 (게임, 나), (게임, 만화).... 이런 식으로 풀어서 스킵그램 리스트에 저장한다.
스킵그램 리스트에는 [target, word]를 쌍으로 가지는 리스트가 저장이 되게 되며 내부적으로는 각 단어의 index 값이 저장된다.
ex) [[1,13],[2,13]....]
def random_batch(data, size):
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(data)), size, replace=False)
for i in random_index:
random_inputs.append(data[i][0])
random_labels.append([data[i][1]])
return random_inputs, random_labels
훈련 시에 스킵그램 리스트에서 단어를 무작위로 추출할 수 있도록 random_batch 함수를 구현하자. 코드의 np.random.choice는 정수 배열과 sampling size, 중복선택 가능 옵션(True면 중복선택 가능)을 입력으로 받아서 sampling size 만큼의 랜덤 index 배열을 리턴한다.
ex ) [1,2,3,4,5], 3, False => [4,2,5]
랜덤 index 배열을 통해 random의 input, label을 리턴한다.
training_epoch = 300 # 훈련 반복 횟수
learning_rate = 0.1 # learning rate
batch_size = 20 # 한번에 학습 할 input data 양
embedding_size = 2 # 단어를 벡터로 표현할 차원 수
num_sampled = 15 # nce_loss를 위한 샘플링 수
voc_size = len(word_list) # 총 vocabulary size
훈련을 위한 hyper parameter 값들을 설정하자. embedding_size의 경우 2차원 좌표상에 표현해 주기 위해 벡터 차원을 두 개로 잡았다. num_sampled의 경우 nce_loss를 위해 필요한데, 간략하게 설명하자면 word 훈련의 경우 모든 단어에 대한 확률 값을 구하지 않고 negative sampling이라고 해서 오답 샘플링을 추린 후 오답에 대한 loss 데이터만 업데이트를 한다. 이를 위한 샘플 데이터이다.
inputs = tf.placeholder(tf.int32, shape=[batch_size])
labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
embeddings = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
selected_embed = tf.nn.embedding_lookup(embeddings, inputs)
nce_weights = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
nce_biases = tf.Variable(tf.zeros([voc_size]))
loss = tf.reduce_mean( tf.nn.nce_loss(nce_weights, nce_biases, labels, selected_embed, num_sampled, voc_size))
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
이제 word를 vector로 변환할 모델을 생성해 보자.
input과 labels 데이터를 넣을 placeholder를 각각 설정해주자. tf nce_loss 함수를 사용하기 위해서는 labels 데이터를 [batch_size, 1] 형태로 넣어주어야 한다.
word를 vector로 표현하기 위한 embedding 벡터를 설정하자. -1.0 ~ 1.0 사이의 정규분포를 가지는 [voc_size * 2] 만큼의 행렬 데이터가 선언이 된다. (가령 단어가 10개라면 embedding 벡터는 [10 * 2] 행렬 값.)
학습 과정에는 실제 단어의 벡터값을 파라미터로 보내지 않고 해당 단어의 index 값을 전달 받게 된다. 각 index에 해당하는 벡터 값을 저장하는 용도의 lookup table을 정의하자. (selected_embed)
ex) embeddings -> input -> selected
[[1,2,3] [2,3] [[4,5,6]
[4,5,6] [7,8,9]]
[7,8,9]]
nce_loss를 계산하기 위한 nce_weights와 nce_bias를 정의하자. 언뜻 이해하기가 어려운데, 아래 그림에서 W'를 nce weight라고 생각하면 된다. (그림에서 bias는 생략됨. 그냥 더해줬다고 판단하면 될 것 같다.)
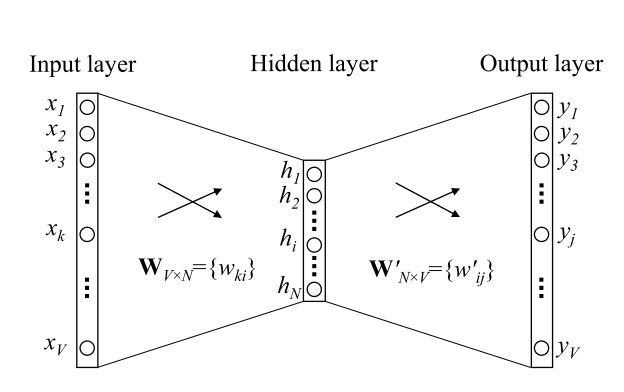
만약 input embedding이 [10 x 2]가 되고 (vocab이 10, 특징 데이터 2) nce_weight가 [10x2], nce_bias가 [10]이라면, 결국 아래의 행렬식으로 계산이 될 것이다.
input layer -> hidden layer -> nce_weight & nce_bias -> output layer
[10x2] -> (concatenate or avr) -> [1x2] * [2x10] + [1x10] -> [1x10]
전체 10x2 행렬 중에 batch size 만큼을 (예를 들어 3) vector average로 계산해서 (각 element를 sum 한 후 3으로 나눔) hidden layer로 만든다. (1x2)
1x2 행렬은 2x10 (nce_weight를 transpose 함)과 행렬 곱을 해서 1x10 행렬을 만들고 [1x10] bias를 더해서 최종 score값을 계산한다.
모든 vocabulary의 개수가 10개이기 때문에 [1x10]의 output이 출력된다.
이렇게 nce_weight와 nce_bias까지 정의했다면, 이젠 nce_loss를 정의하자.
일반적으로 많이 쓰는 cross entropy의 경우, 모든 label에 대한 entropy를 구한 후 합해서 loss를 계산하고 있다.
하지만 word인 경우 만약 단어 vocabulary가 10만개라고 한다면, 1개의 단어 학습 시, 10만개에 대한 softmax를 구해서 확률값을 찾고, 해당 확률 값에 대한 cross entropy를 계산해야 한다.
이런 계산 성능을 보다 향상시키기 위해서, 모든 단어에 대한 확률값을 찾는게 아니라 정답셋 1개와 오답셋(샘플링 개수) 만 확률값을 찾아 계산하는 방식을 Negative sampling이라고 하고, 이를 위해 사용하는게 바로 nce_loss 함수이다.

왼쪽의 정답이 될 확률 값은 크게 만들고, 오른쪽 오답에 대한 값들의 합은 최대한 작게 만듬으로써 weight 학습을 진행한다.
마지막으로 adamOptimizer를 사용해서 최적화를 만든다.
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for step in range(1, training_epoch + 1):
batch_inputs, batch_labels = random_batch(skip_grams, batch_size)
_, loss_val = sess.run([train_op, loss], feed_dict={inputs: batch_inputs, labels: batch_labels})
if step % 10 == 0:
print("loss at step ", step, ": ", loss_val)
trained_embeddings = embeddings.eval()
이제 모델을 다 만들었으니, 학습을 진행하자. 학습은 이전 방법처럼 매우 간단하다.
변수 초기화 시켜주고, epoch 만큼 학습을 진행한다. data를 가져올 때는 위에서 만든 random_batch 함수를 이용해서 random으로 적절히 가져오자.
train_op와 loss 함수에 대해 run을 실행시키고, 10 단계마다 loss 값을 찍자.
epoch 학습이 완료되면 최종 embeddings 값을 trained_embeddings에 저장하자. (좌표 찍기 위함 용)
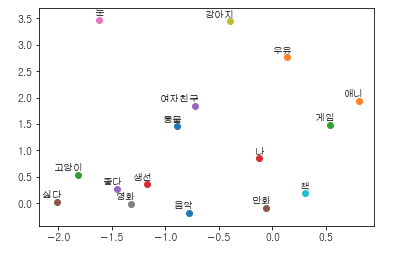
for i, label in enumerate(word_list):
x, y = trained_embeddings[i]
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
이제 마지막 단계다. 위에서 저장한 trained_embeddings 값을 x,y로 나누고 x,y값을 plt scatter에 넣어주자. annotation 설정하고 마지막에 plt.show()를 하면 아래의 좌표 그래프가 나타나게 된다.